bin folder that includes the jar files. 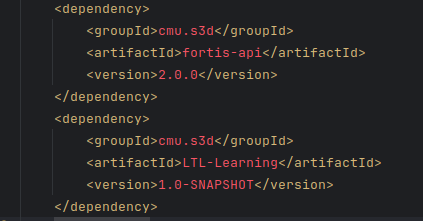
<2024-09-17 মঙ্গল>
We completed 3 approaches before, involving UML to LTL parsing, converting big formally defined systems into UML and finding more case studies. We document the next approaches here.
I am trying to change codebase of Fortis - a research paper made by a PhD student in CMU. So I need to run that codebase for that, firstly.
We mainly encounter these issues after somehow resolving dependency issue.
| Error type |
|---|
| Unresolved reference |
| Cannot infer a type for this parameter |
| Not enough information to infer type variable |
| Overload resolution ambiguity |
And they occur from:
| Unresolved reference: X | Count |
|---|---|
| Word | 306 |
| NFA | 108 |
| Alphabets | 34 |
| Util | 108 |
| automaton | 120 |
| variable S | 70 |
| AutomatonBuilders | 22 |
| TSTraversal | 976 |
These classes are in net.automatalib. It imports properly and we have also tried with v0.9.0-0.11.0. And most importantly, it does not show dependency error that it can't find a library. It just says:
These dependencies are not available in maven repository. So they must be available as jar files online. But I could not find any such jar files! And I checked .gitignore file of the fortis-core repository and it excluded bin folder that includes the jar files.
Possible reasons:
As you can see in the list of packages, there is no common package. I checked last 30 commits randomly and did not find this folder in ANY of the commits! Its also not in .gitignore 
Possible solutions:
Their pom file is also incomplete! We had to manually add 1 dependency, but it still shows error. The eternally long list of errors can be found here
The goal is to generate costs and use that to generate graphs. Then we will inspect how effective those generations are.
The input and prompts can be found in the dataset. Now let us consutrct a dataset.
| Dataset | Size | Result | ChatGPT |
|---|---|---|---|
| Promptv1 | 5 systems | Failed to find a solution. | chatGPT logs |
We skip totalcost for now. It makes the process complex. Now we need to run Fortis to understand how good the cost assignments are.
There are existing works that uses eye gaze tracking to assess the human comprehension complexity of a diagram.
We now start collecting data for evaluating it. Our possible data sources are:
| Dataset source | N | Challenge |
|---|---|---|
| Fortis Codebase | 7 systems | Big and complex |
| LTSA tool examples | 97 examples | Algorithmic examples |
| 2 papers using LTL systems as part of process 1, 2 | 2 systems | Extremely complex |
But now we do have a a confusion. How do express the LTL codebase as a graph? Perhaps Finite State Machine translations can help. We found a solution! LTSA tool has a feature of exporting LTL code to aut format, which is basically transitions between states. Using that, we can draw the UML diagrams. The graph itself is enough!
Techniques from psychometrics and cognitive psychology, such as the paired comparison method, can be utilized. This approach has been used to assess preferences or perceived complexity between design alternatives. Participants are asked to assess which item in each pair is preferred, better, or in this context, more complex. For each design, count how many times it was preferred over others. This count will be the design's score. Rank the designs based on their scores from highest to lowest. The higher the score, the more complex the design is perceived to be.
We can use it to estimate design comprehension of users - what do they understand by reading the problem details and the design?
A/B testing, also known as split testing, is a method used to compare two or more variations of a design (such as a website, user interface, or product feature) to determine which one performs better based on specific metrics.Hypothesis here can be: "Changing the button color from blue to green will increase click-through rates." We can use it in our case with the hypothesis, "Which design takes longer to understand?". Annotators will annotate and note down their understanding. Using original problem definition (hidden) and user's understanding, we will analyze how well they understood the design within that time. If a design takes long time to understand but still the user understands it wrong, then its probably a bad design.
Now we need to formalize the annotation process.
R. Wang, Y. Zhou, S. Chen, S. Qadeer, D. Evans, and Y. Gurevich, “Explicating sdks: Uncovering assumptions underlying secure authenti- cation and authorization,” in Proceedings of the 22th USENIX Security Symposium, Washington, DC, USA, August 14-16, 2013, 2013, pp. 399– 314.↩︎
S. Sun and K. Beznosov, “The devil is in the (implementation) details: an empirical analysis of OAuth SSO systems,” in the ACM Conference on Computer and Communications Security, CCS’12, Raleigh, NC, USA, October 16-18, 2012, 2012, pp. 378–390.↩︎